团队2018级研究生吴益同学的论文“Multi-modal 3D object detection by 2D-guided precision anchor proposal and multi-layer fusion”被SCI期刊《Applied Soft Computing》 录用,祝贺!
Abstract:
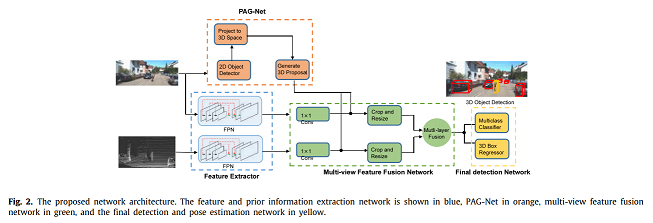
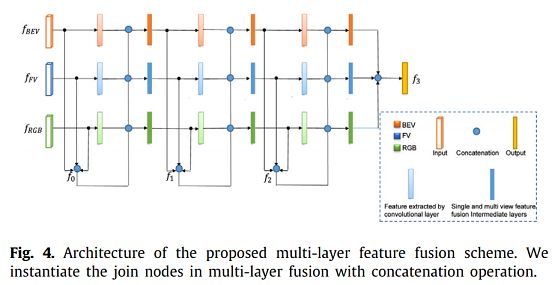
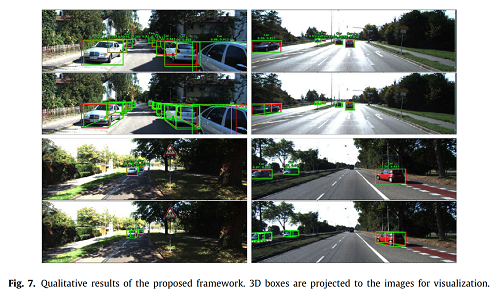
3D object detection, of which the goal is to obtain the 3D spatial structure information of the object, is a challenging topic in many visual perception systems, e.g., autonomous driving, augmented reality, and robot navigation. Most existing region proposal network (RPN) based 3D object detection methods generate anchors in the whole 3D searching space without using semantic information, which leads to the problem of inappropriate anchor size generation. To tackle the issue, we propose a 2D-guided precision anchor generation network (PAG-Net). Specifically speaking, we utilize a mature 2D detector to get 2D bounding boxes and category labels of objects as prior information. Then the 2D bounding boxes are projected into 3D frustum space for more precise and category-adaptive 3D anchors. Furthermore, current feature combination methods are early fusion, late fusion, and deep fusion, which only fuse features from high convolutional layers and ignore the data missing problem of point clouds. To obtain more efficient fusion of RGB images and point clouds features, we propose a multi-layer fusion model, which conducts nonlinear and iterative combinations of features from multiple convolutional layers and merges the global and local features effectively. We encode point cloud with the bird’s eye view (BEV) representation to solve the irregularity of point cloud. Experimental results show that our proposed approach improves the baseline by a large margin and outperforms most of the state-of-the-art methods on the KITTI object detection benchmark.
Download: [官方链接] [preprint版本]
Keywords: 3D object detection, Multi-modal, Autonomous driving, Feature fusion, Point cloud.
Photos: