团队论文“Distribution-aware Noisy-label Crack Segmentation”IEEE国际机器人与自动化会议《IEEE International Conference on Robotics and Automation》
Abstract:
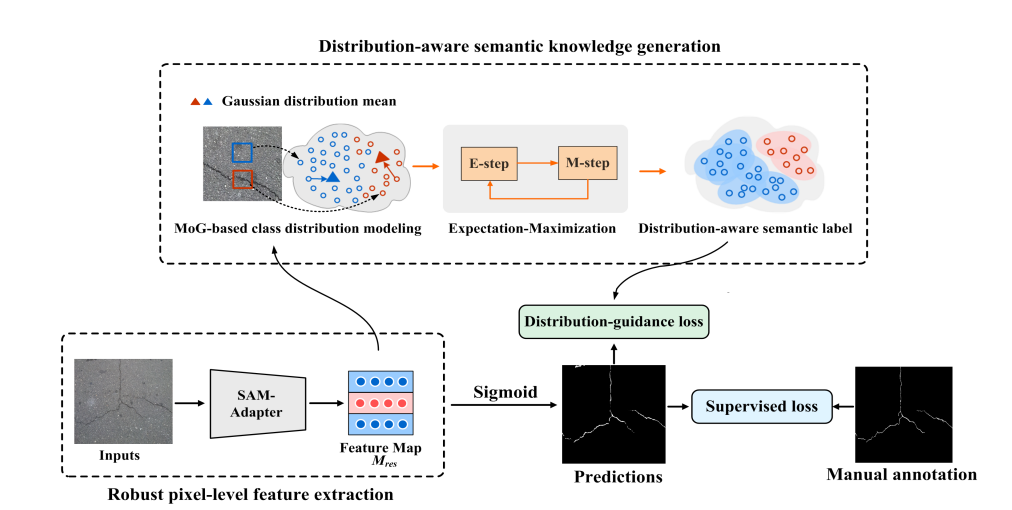
Road crack segmentation is critical for robotic systems tasked with the inspection, maintenance, and monitoring of road infrastructures. Existing deep learning-based methods for crack segmentation are typically trained on specific datasets, which can lead to significant performance degradation when applied to unseen real-world scenarios. To address this, we introduce the SAM-Adapter, which incorporates the general knowledge of the Segment Anything Model (SAM) into crack segmentation, demonstrating enhanced performance and generalization capabilities. However, the effectiveness of the SAM-Adapter is constrained by noisy labels within small-scale training sets, including omissions and mislabeling of cracks. In this paper, we present an innovative joint learning framework that utilizes distribution-aware domain-specific semantic knowledge to guide the discriminative learning process of the SAM-Adapter. To our knowledge, this is the first approach that effectively minimizes the adverse effects of noisy labels on the supervised learning of the SAM-Adapter. Our experimental results on two public pavement crack segmentation datasets confirm that our method significantly outperforms existing state-of-the-art techniques. Furthermore, evaluations on the completely unseen CFD dataset demonstrate the high cross-domain generalization capability of our model, underscoring its potential for practical applications in crack segmentation.
Download: [preprint版本]
Keywords: SAM-Adapter,Crack Detection
Photos: